Trusted by enterprise teams and partners








Deterministic AST parsing with AI augmentation. Column-level lineage, visual execution, automatic documentation — all running on your infrastructure. No hallucinations. No data leaving your network.
A deterministic parser that never hallucinates, paired with an AI engine that knows your codebase. The parser always has the final word.
AST-based, compiler-grade analysis. Same input always produces the same output. Column-level lineage, STTM, code conversion — all 100% reproducible.
AI that knows your codebase, lineage, and data flows. Suggests, explains, and generates — but the parser always validates. AI never has the final word on correctness.
No consultants, no external dependencies. Deploy the PyFluent Docker image behind your firewall. Your code and data never leave your network.
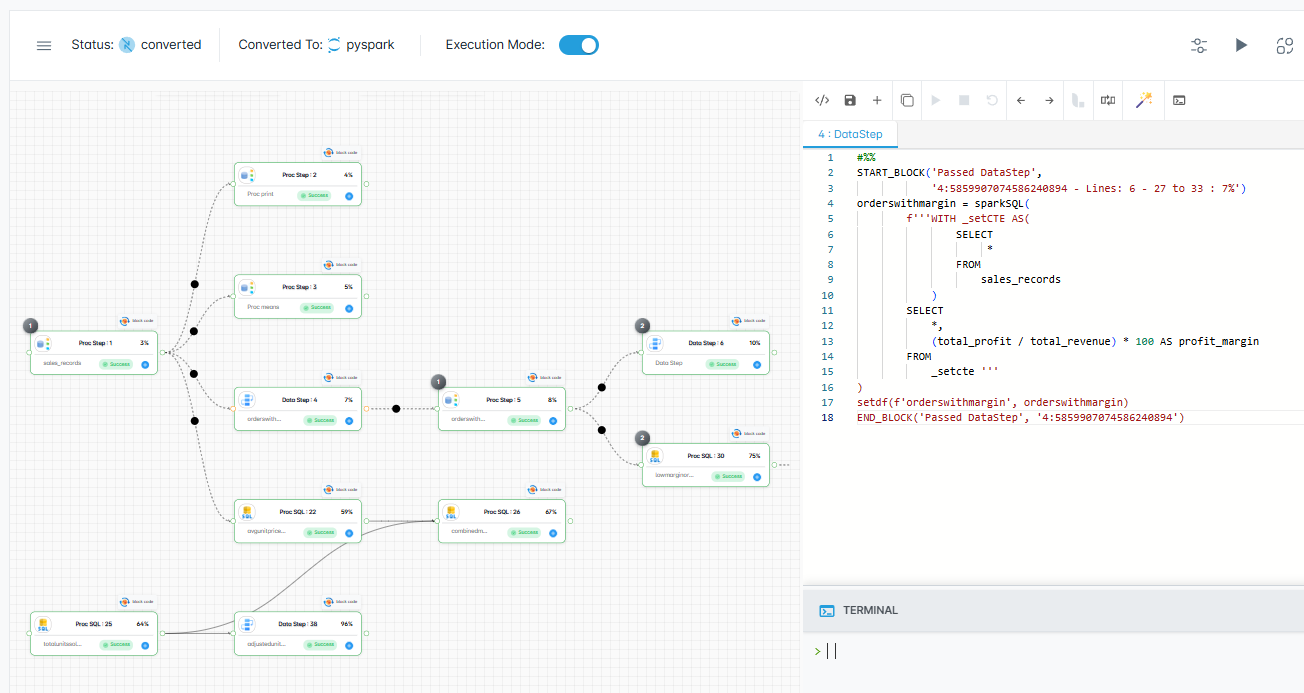
A visual development environment where lineage updates in real time, execution is step-by-step, and documentation writes itself.
A lineage graph updates in real time beside your code. Trace every column's origin and catch broken dependencies before you run anything.
Run pipelines step-by-step on Databricks and Snowflake. See exactly where execution stops, what failed, and why.
Auto-generated docs, inline AI explanations, and STTM tables teach your team as they work. Junior developers write senior-quality code.
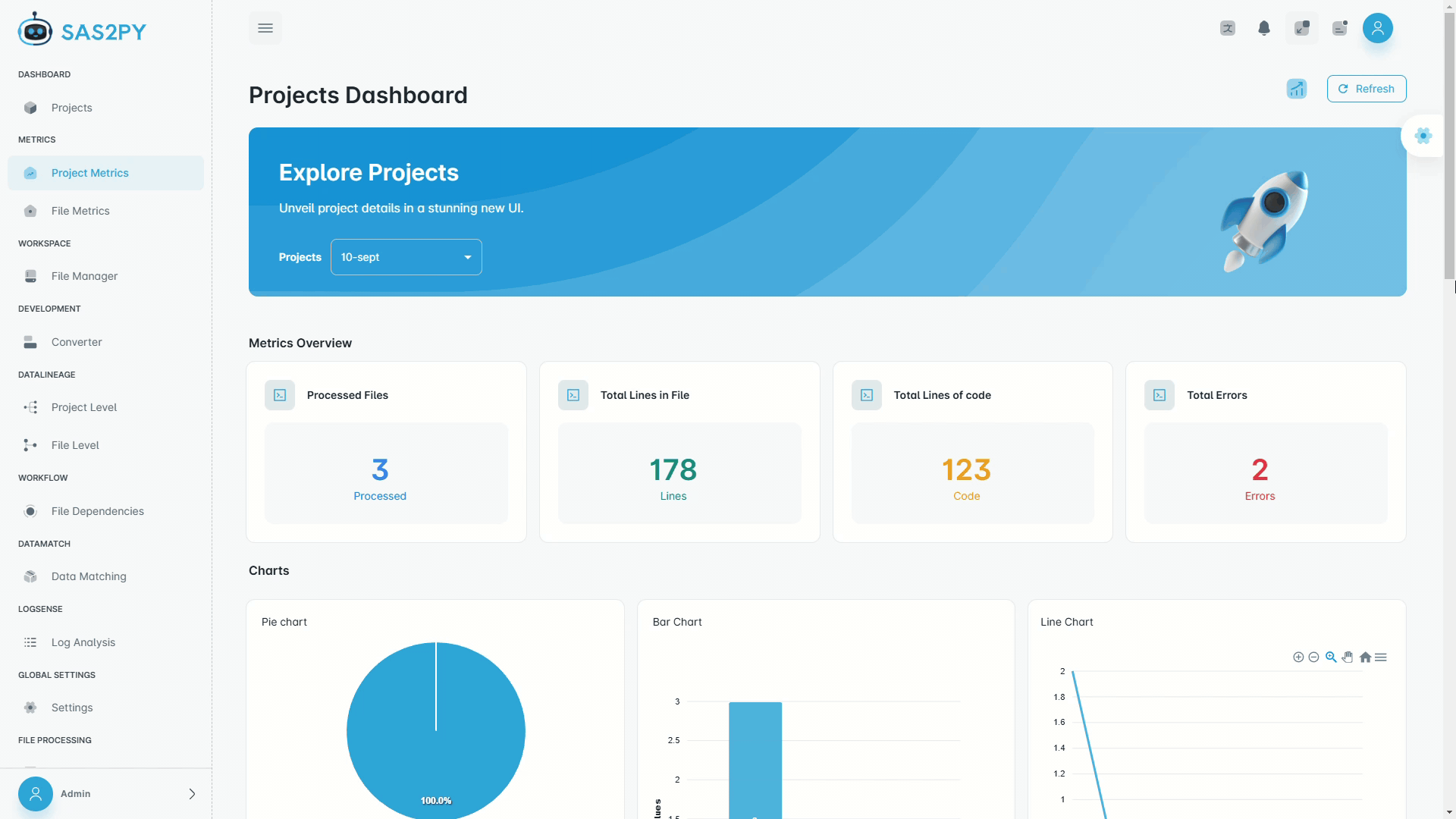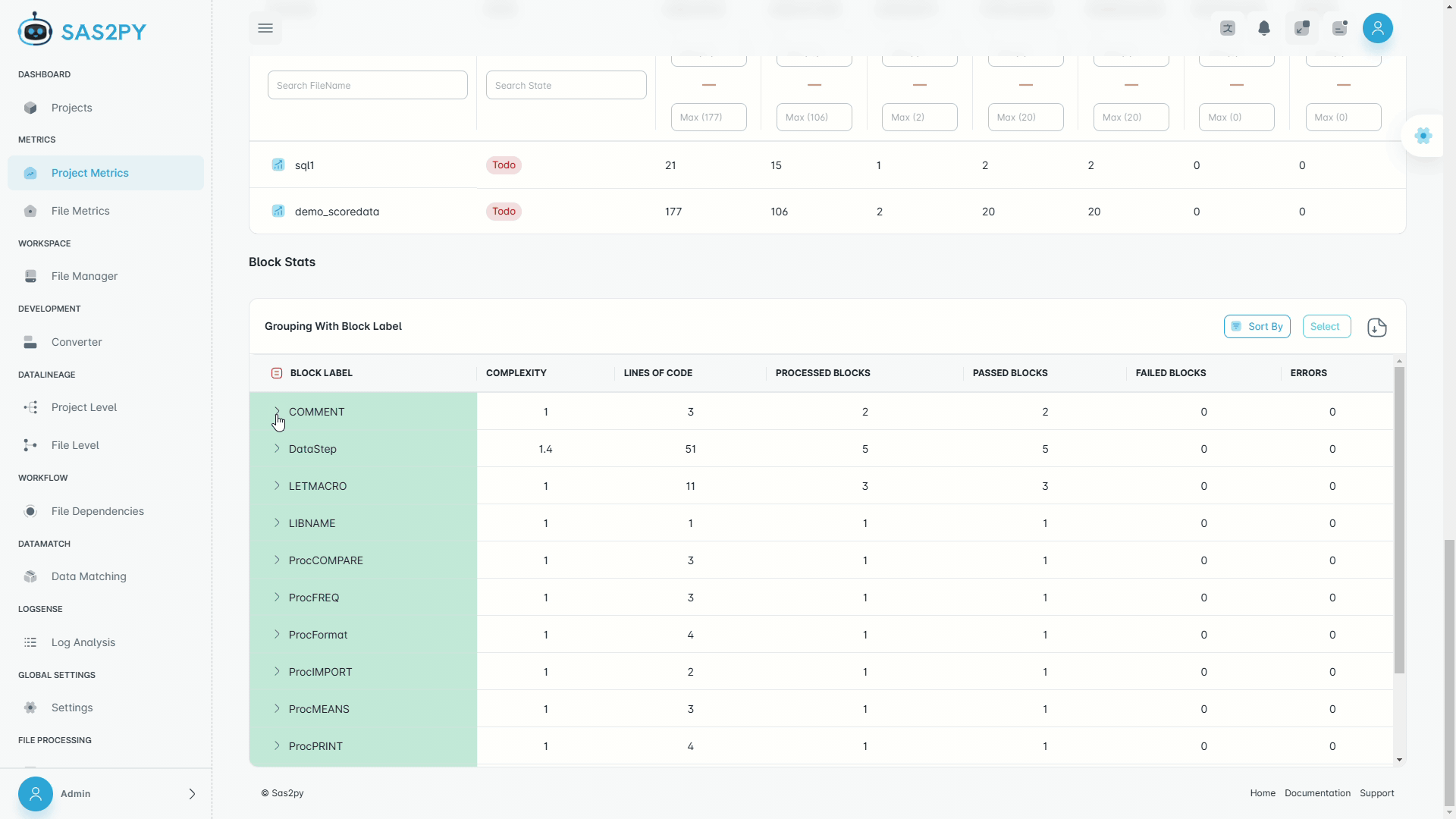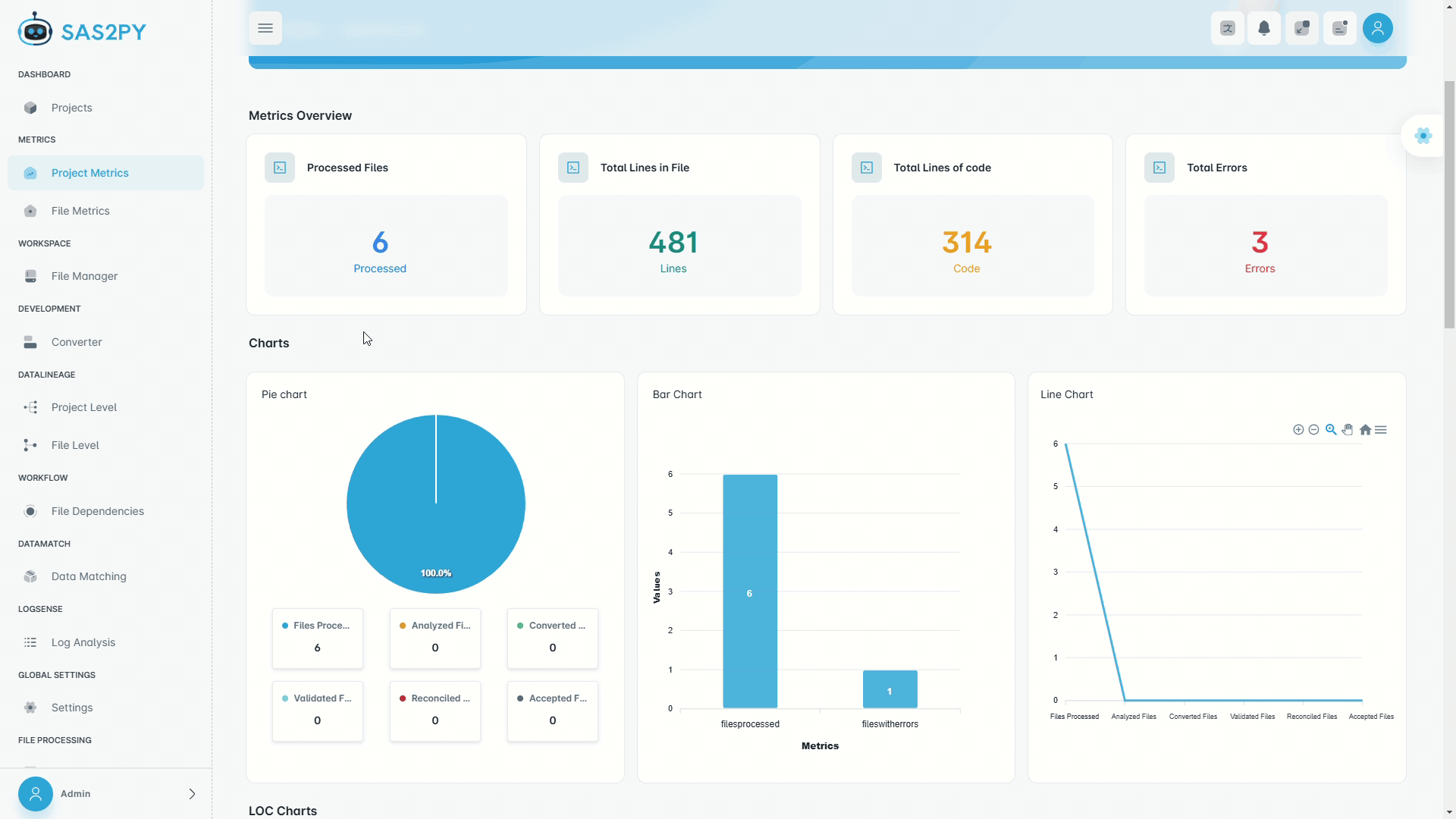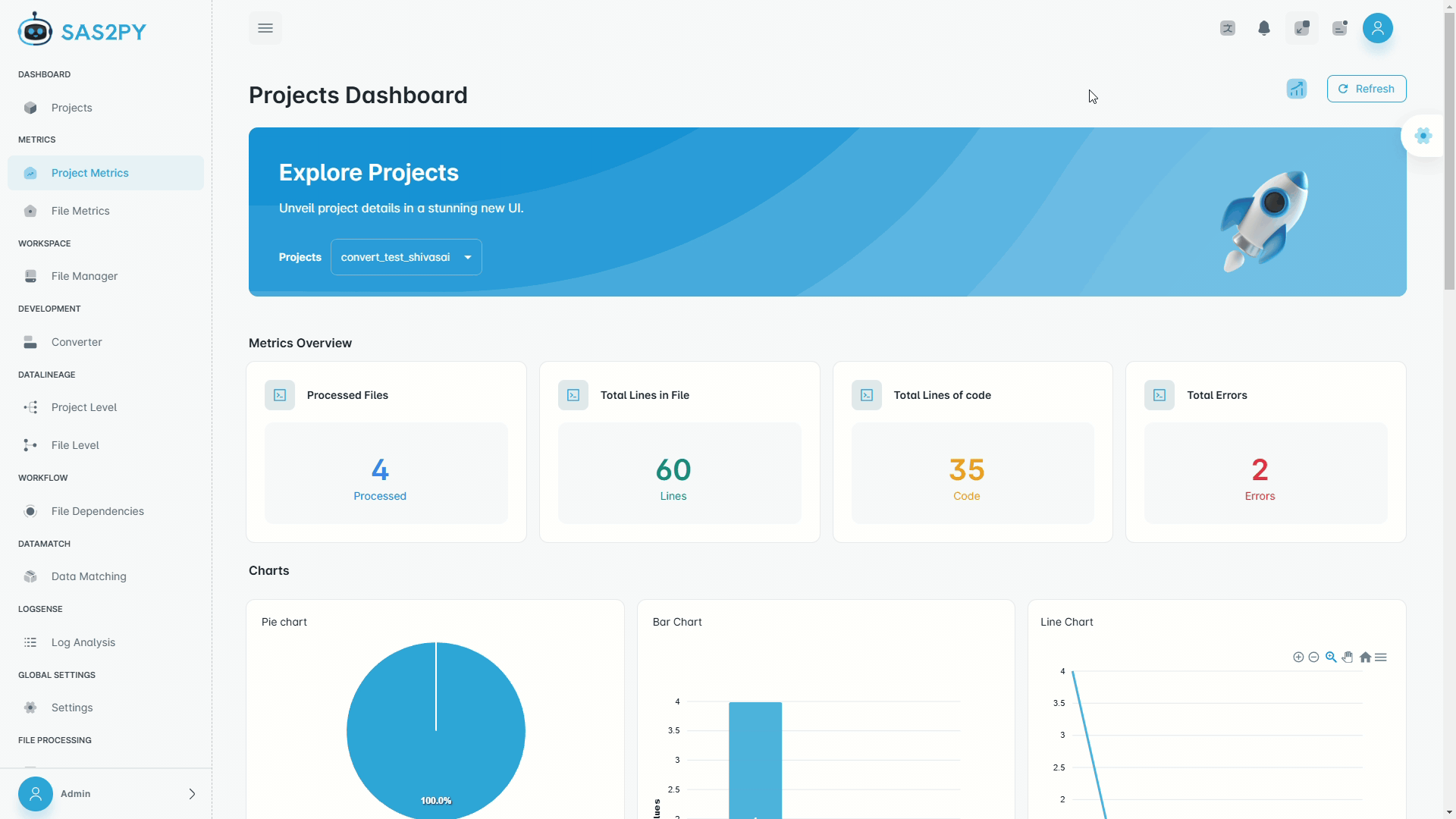
Inline table views, schema cards, and distribution charts beneath each step. Explore data visually without writing profiling code.
Docstrings, data dictionaries, and pipeline docs generated from real code and lineage. Always accurate, always current.
Export to production Python modules, FastAPI endpoints, Airflow DAGs, or Spark jobs. Clean, typed, production-ready output.
Watch how PyFluent transforms your Python development workflow — from analysis to deployment.
Import Python, PySpark, pandas, or SQL code. The deterministic parser extracts column-level lineage, STTM, and project metrics automatically.
The AI engine suggests optimizations based on your actual data flows and lineage. Convert between frameworks, optimize queries, and improve performance.
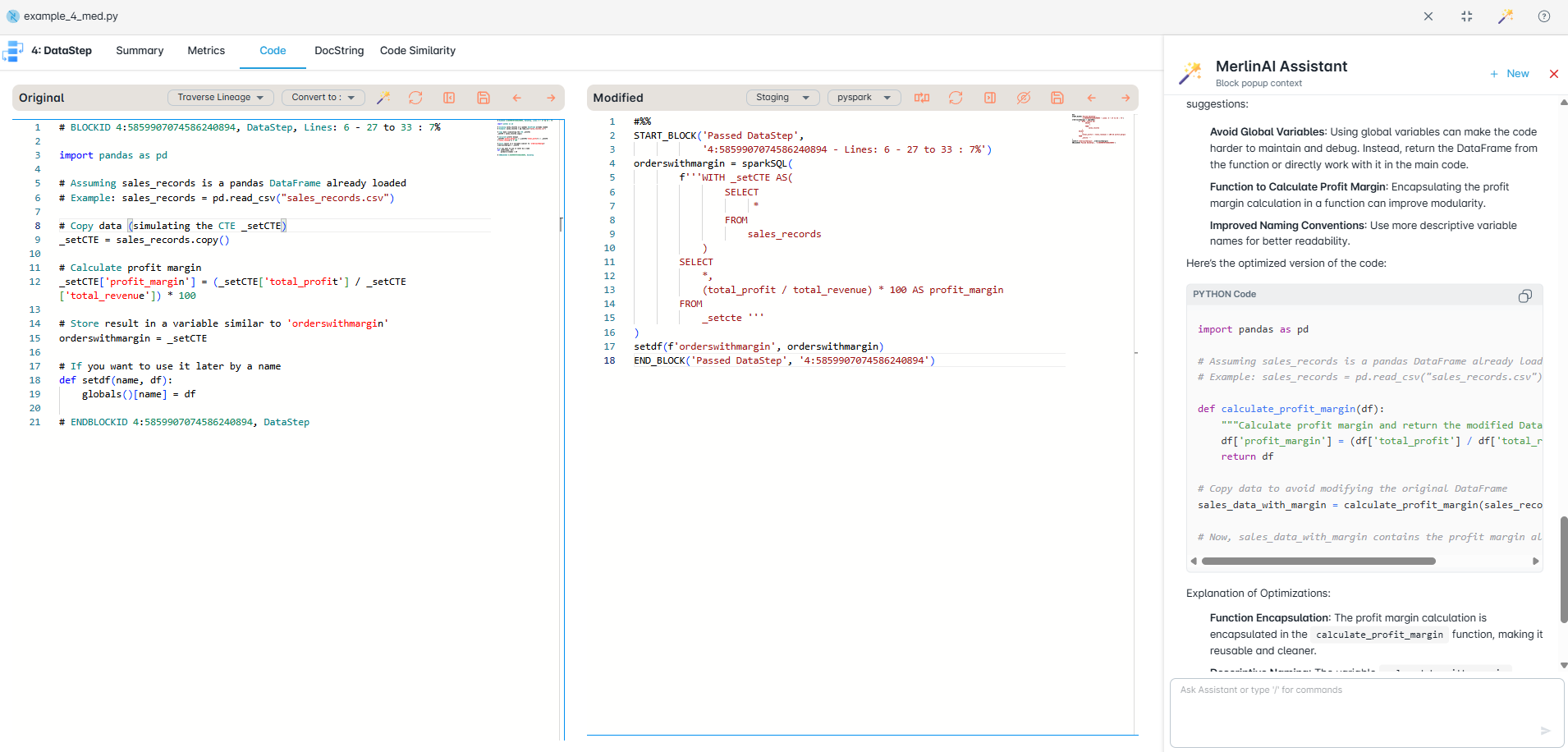
Write code in the visual editor with a real-time lineage graph beside you. See exactly how data flows through your pipeline as you type.
Run validation checks against your data. Compare source and target at the column level. The deterministic engine ensures 100% reproducible results.
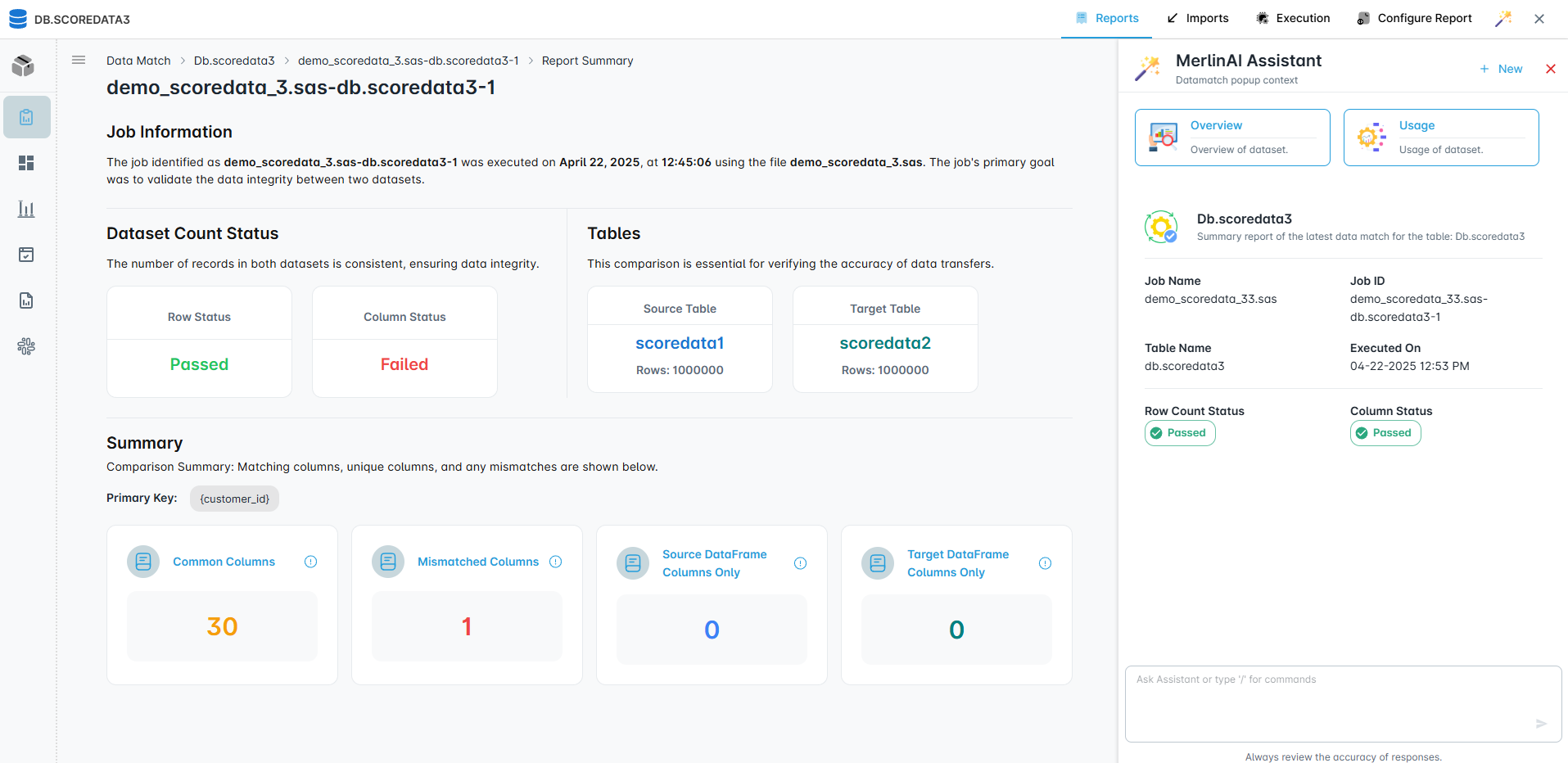
The AI assistant helps you prepare code for production. Auto-generates documentation, suggests error handling, and exports to your target platform.
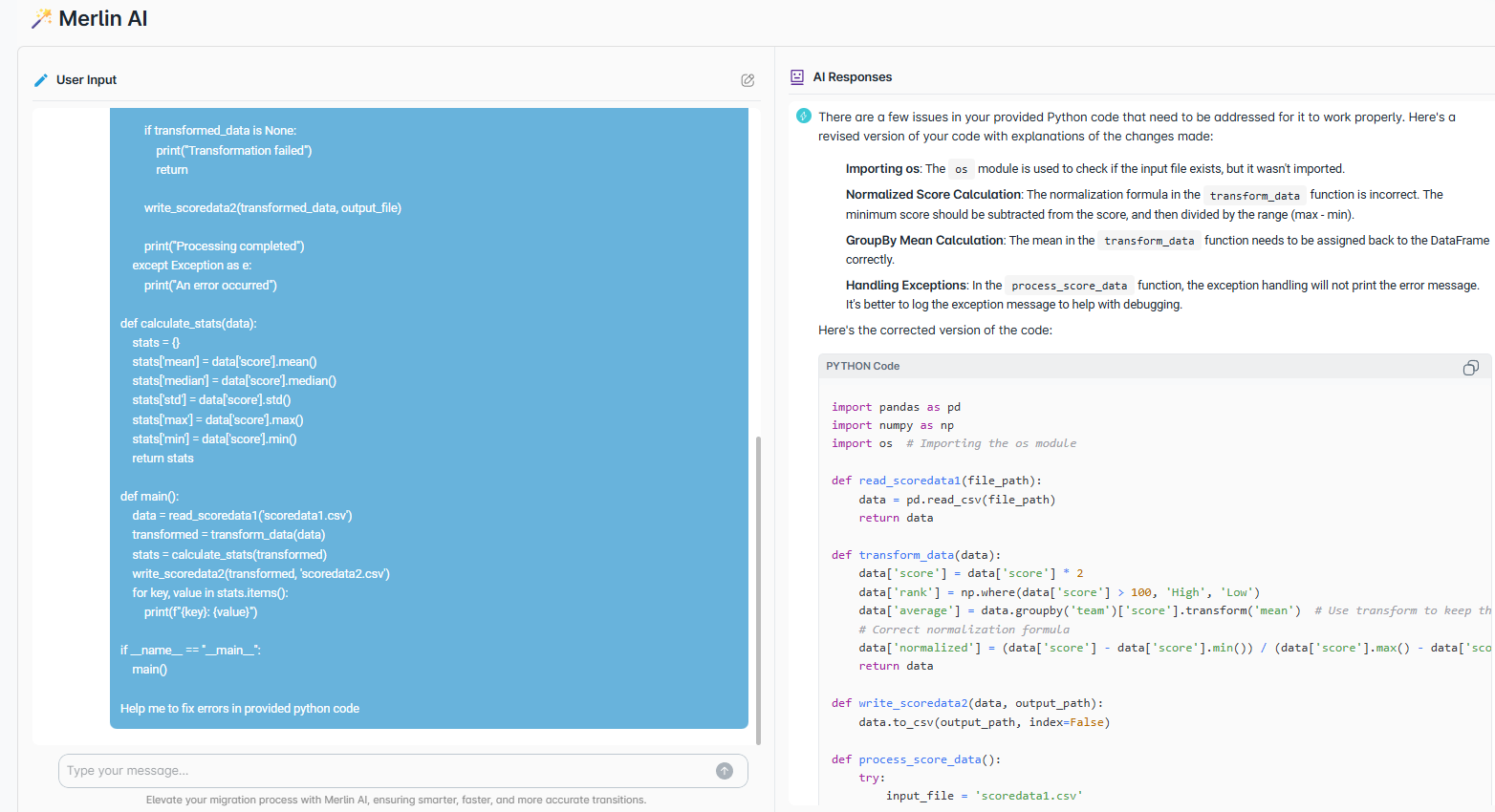
Everything you need to analyze, convert, trace, validate, document, and execute Python code — without stitching together a dozen tools.

Automated complexity scoring, dependency risk heatmaps, and technical debt quantification across your entire codebase.
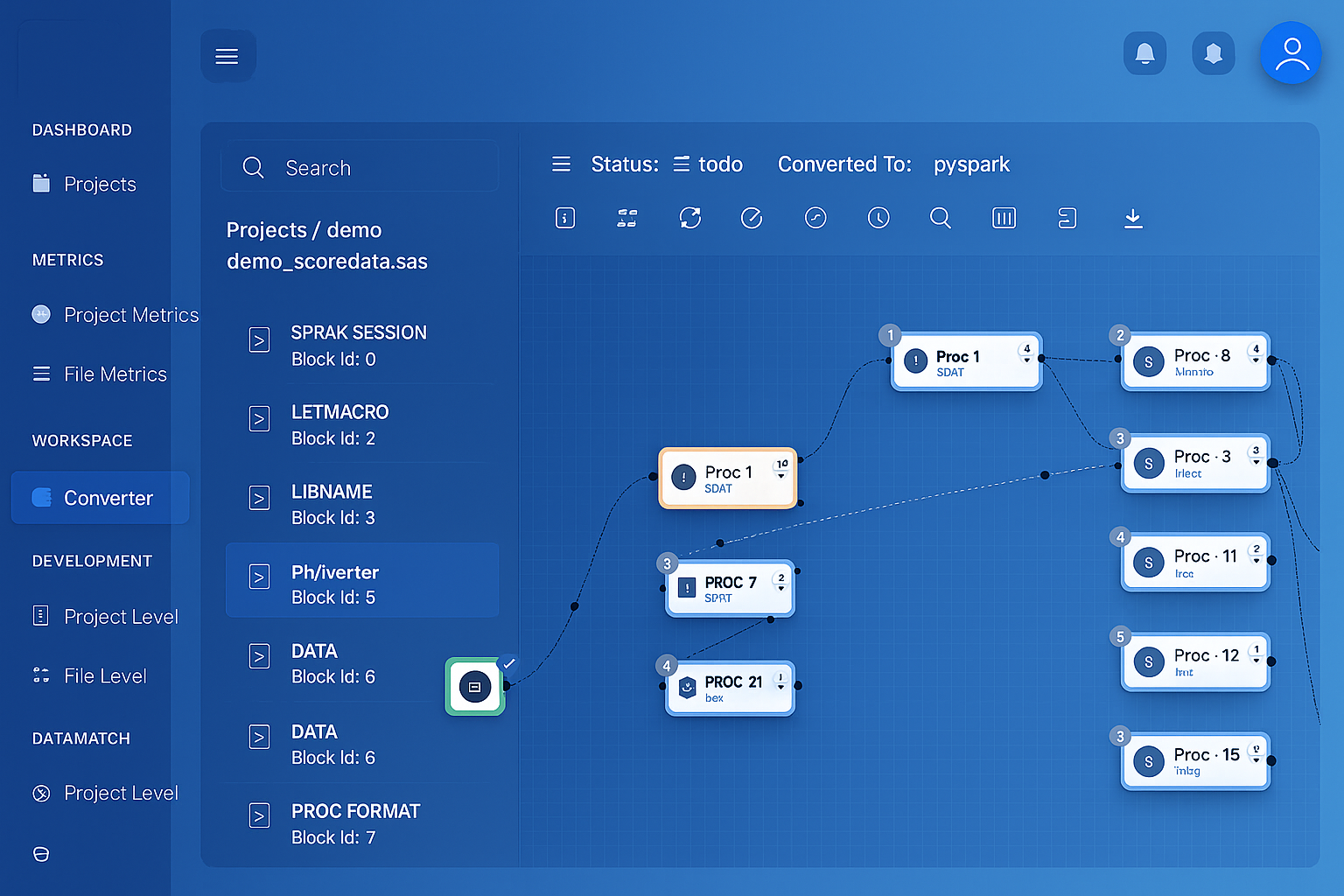
Interactive column-level lineage graphs. Trace any output column back to its source through every transformation. No annotations required.
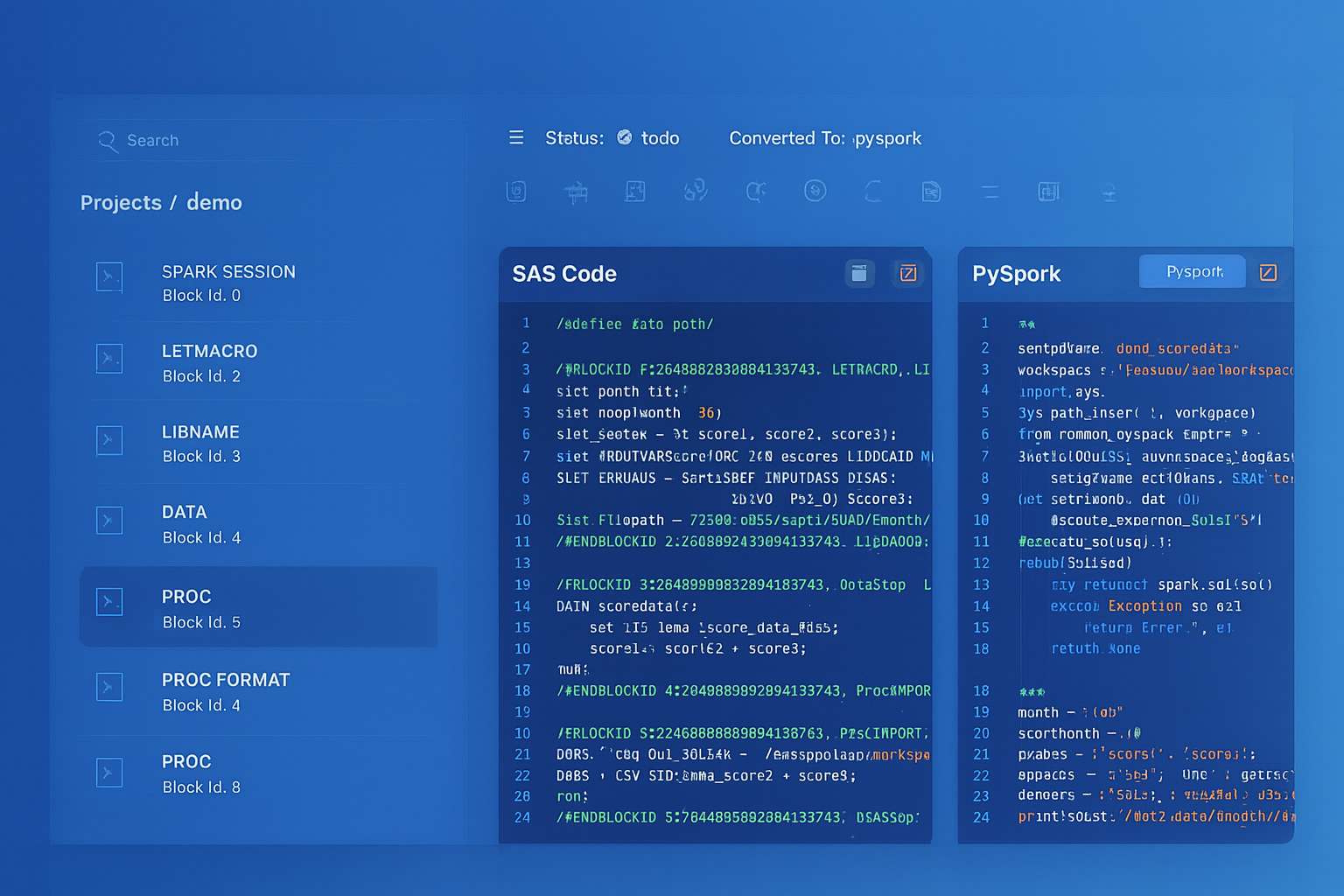
Convert SAS, DataStage, BTEQ, and SQL to production-quality Python/PySpark. Deterministic parsing ensures accurate, reproducible output.
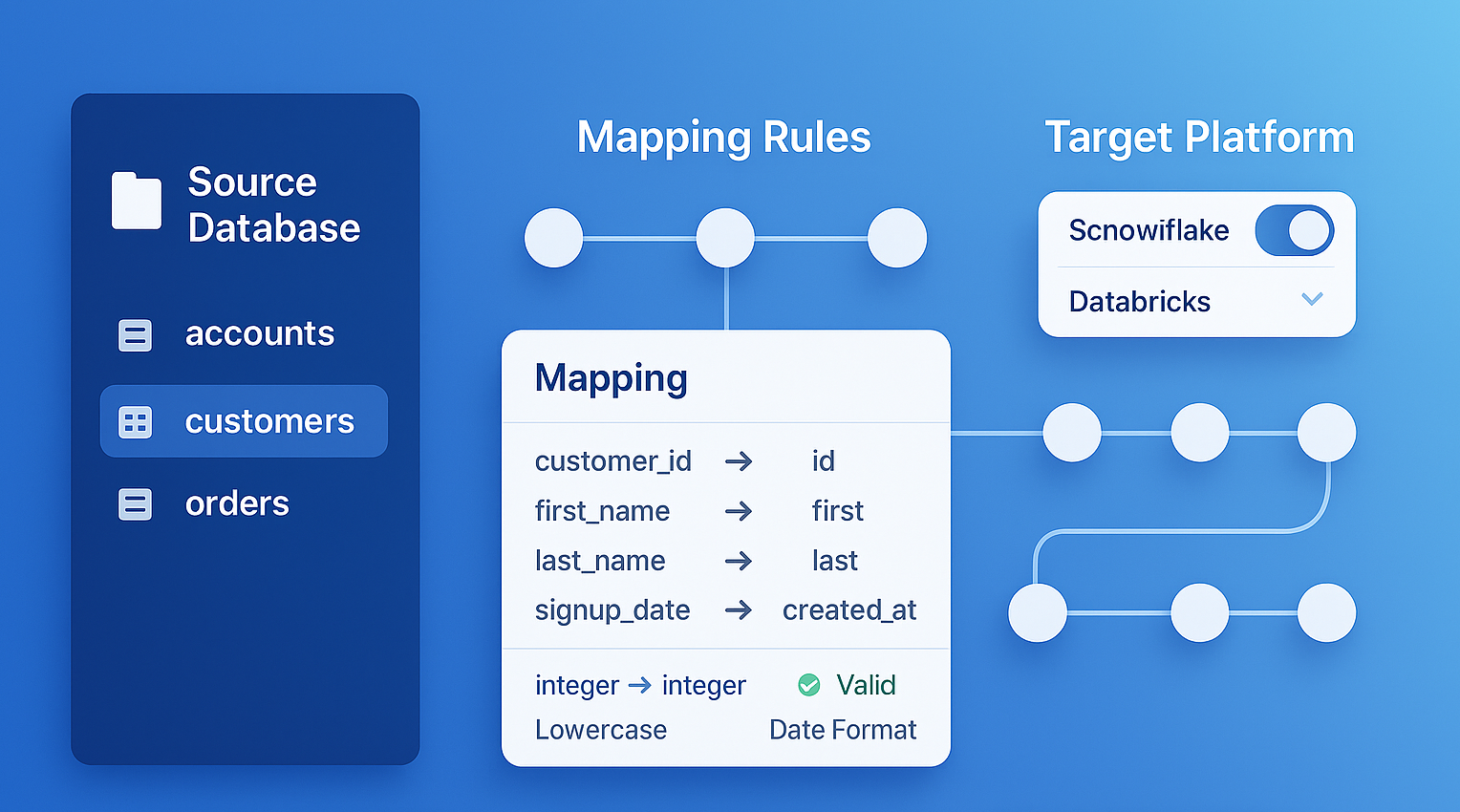
Automatic Source-to-Target Transformation Mapping. Every column's journey from source to target, extracted by the parser — not generated by AI.
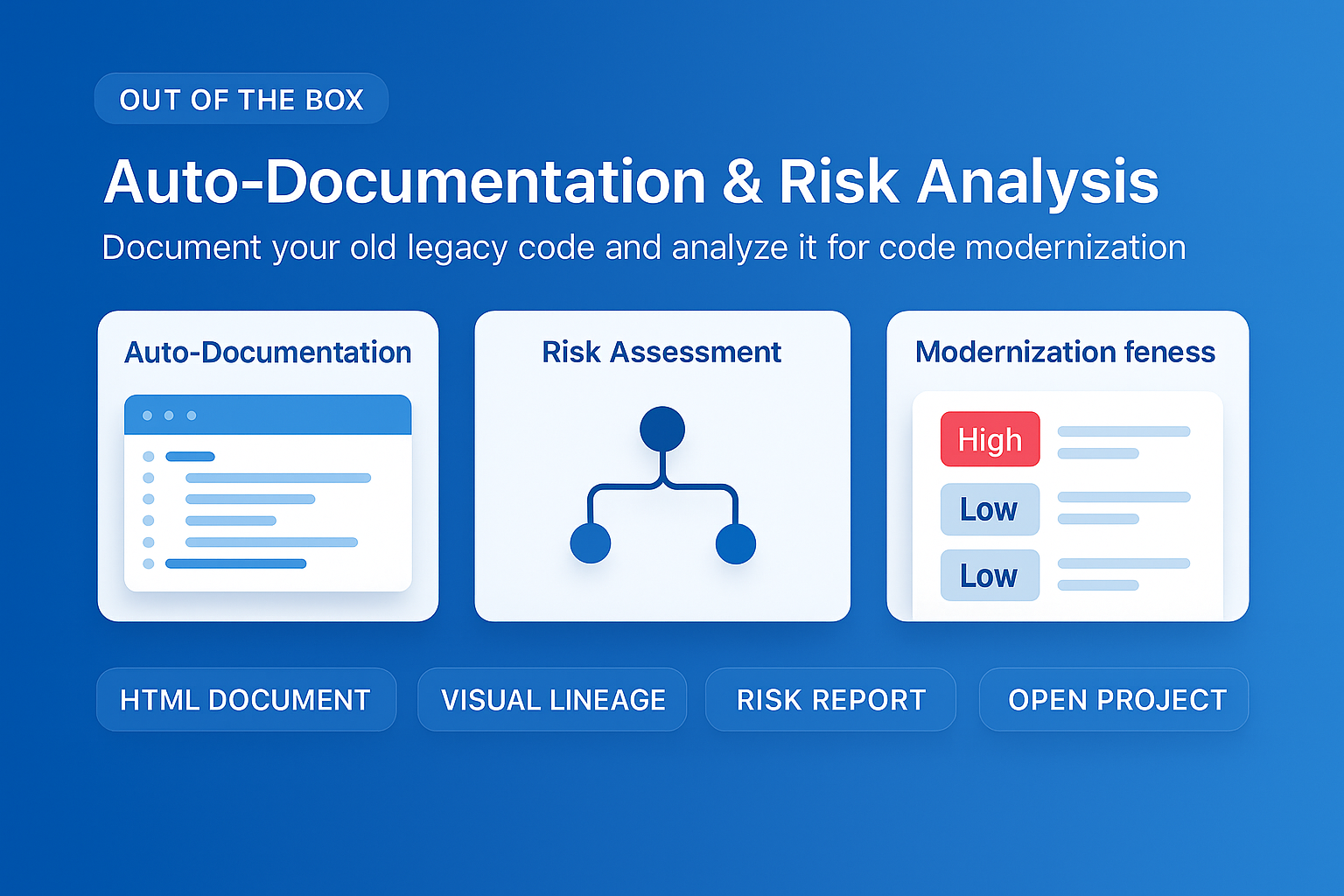
Docstrings, data dictionaries, pipeline docs, and compliance reports — generated from actual code and lineage. Always accurate, never stale.
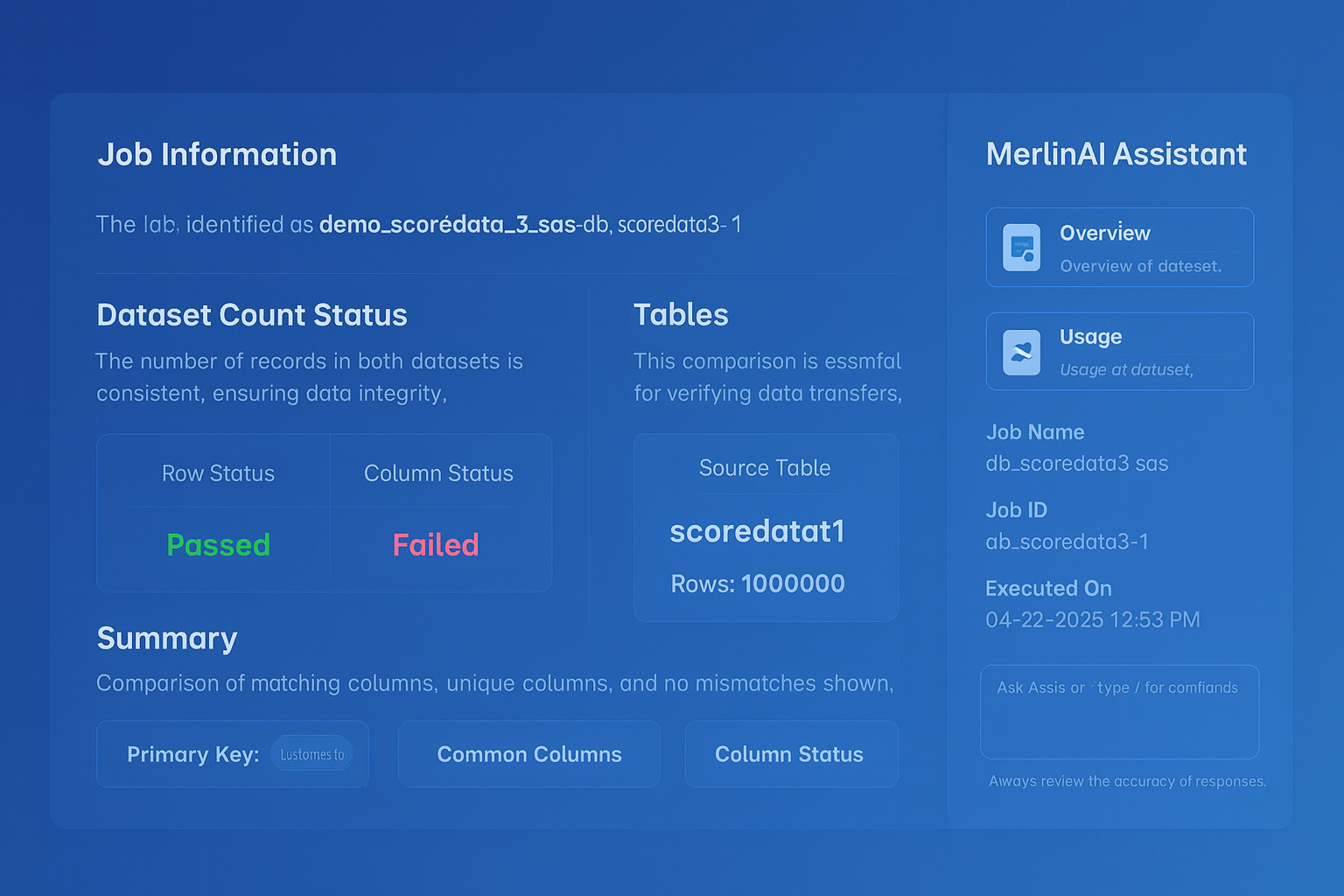
Column-level source-to-target data comparison. Automated regression testing. Deterministic validation with clear pass/fail results.
Run pipelines on Databricks and Snowflake with full visibility. See exactly where execution stops and why.
Built from the ground up for deterministic correctness. Every other tool is AI-first. PyFluent is parser-first, AI-augmented.
Column-level STTM is extracted by the parser, not generated by AI. 100% reproducible. Run it Monday or Friday — identical results every time.
Deploy behind your firewall. Air-gap ready. No SaaS, no telemetry, no phone-home. Source code and lineage stay in your network. Always.
No consultants needed. Install, connect data sources, and be productive the same day. The visual editor makes onboarding effortless.
Analysis, conversion, lineage, validation, documentation, and execution. No stitching Jupyter + Airflow + Great Expectations + dbt + custom scripts.
Interactive lineage graphs, step-by-step execution, data previews, and schema cards. Understand your pipeline at a glance, not by reading 10,000 lines of code.
Full audit trails, compliance reports, GDPR/CCPA data mapping, and SOX controls. The platform your compliance team will thank you for.
On-premises deployment, full column-level audit trails, and auto-generated compliance reports.
No training required. No professional services. Download, install, connect — and your team is productive today.
Deploy the PyFluent Docker image on your servers. Connect to Databricks, Snowflake, S3, or local files. The deterministic parser starts indexing immediately.
Open the visual editor. Lineage graphs and STTM tables are already generated. AI explains your code and auto-generates documentation.
Convert legacy code. Run visual execution on your cloud platform. Validate with deterministic data matching. Ship with confidence.
Every developer writes better Python because the platform teaches them. Lineage stays current. Documentation never goes stale.